

Stackdriver Logging, parte de nuestro conjunto de herramientas de administración de operaciones en Google Cloud, está diseñado para administrar y analizar registros a escala para ayudarlo a solucionar problemas en su entorno de nube híbrida y obtener información de sus aplicaciones. Pero el gran volumen de datos generados por la máquina puede suponer un desafío al buscar en los registros.
A través de nuestros años de trabajo con los usuarios de Stackdriver Logging, hemos identificado las formas más fáciles y las mejores prácticas para obtener el valor que necesita de sus registros. Hemos recopilado nuestros consejos favoritos para un análisis de registro más efectivo y una resolución de problemas rápida, incluidas algunas características nuevas para ayudarlo a obtener valor de sus registros de manera rápida y fácil: búsquedas guardadas, una biblioteca de consultas, soporte para tablas de partición al exportar registros a BigQuery, y más.
- Aproveche el lenguaje de consulta avanzado
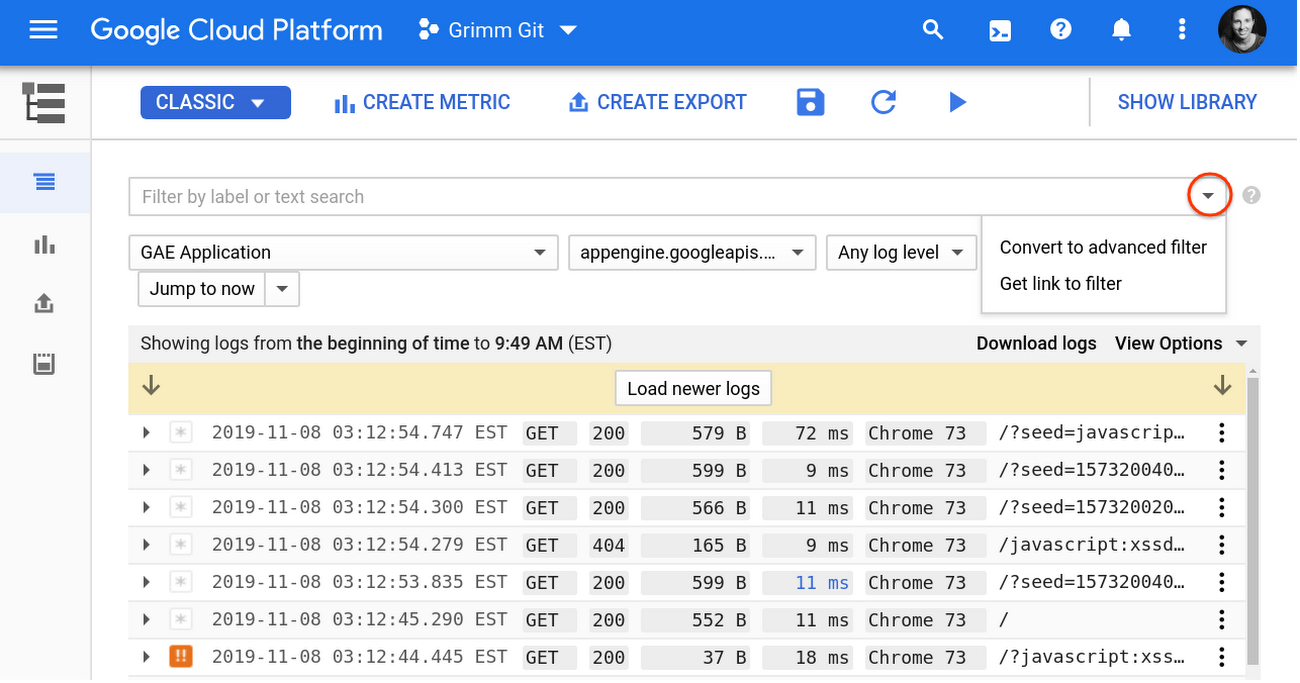
El modo básico predeterminado para buscar en los registros de Stackdriver es usar los menús desplegables para seleccionar el recurso, el registro o el nivel de gravedad. Aunque esto hace que sea increíblemente fácil comenzar con sus registros, la mayoría de los usuarios gravitan hacia el filtro avanzado para hacer consultas más complejas, como se muestra aquí:
Operadores de comparación:
= # igual
! = # no es igual
<> = <= # ordenamiento numérico
: # “has” coincide con cualquier subcadena en el campo de entrada de registro
Operadores booleanos: por defecto, varias cláusulas se combinan con AND, aunque también puede usar OR y NOT (¡asegúrese de usar mayúsculas!)
Funciones: ip_in_net () es un favorito para analizar registros de red, como este:
ip_in_net (jsonPayload.realClientIP, “10.1.2.0/24”)
Consejo profesional: incluya el nombre de registro completo, el rango de tiempo y otros campos indexados para acelerar los resultados de búsqueda. Vea estos y otros consejos sobre cómo acelerar el rendimiento.
Nueva biblioteca de consultas: hemos consultado a expertos de todo Google Cloud para recopilar algunas de nuestras consultas avanzadas más comunes por caso de uso, incluidos Kubernetes, registros de seguridad y redes, que puede encontrar en una nueva biblioteca de consultas de muestra en nuestra documentación. ¿Hay algo diferente que te gustaría ver? Haga clic en el botón “Enviar comentarios” en la parte superior de la página de consultas de muestra y háganos saber.
- Personaliza tus resultados de búsqueda
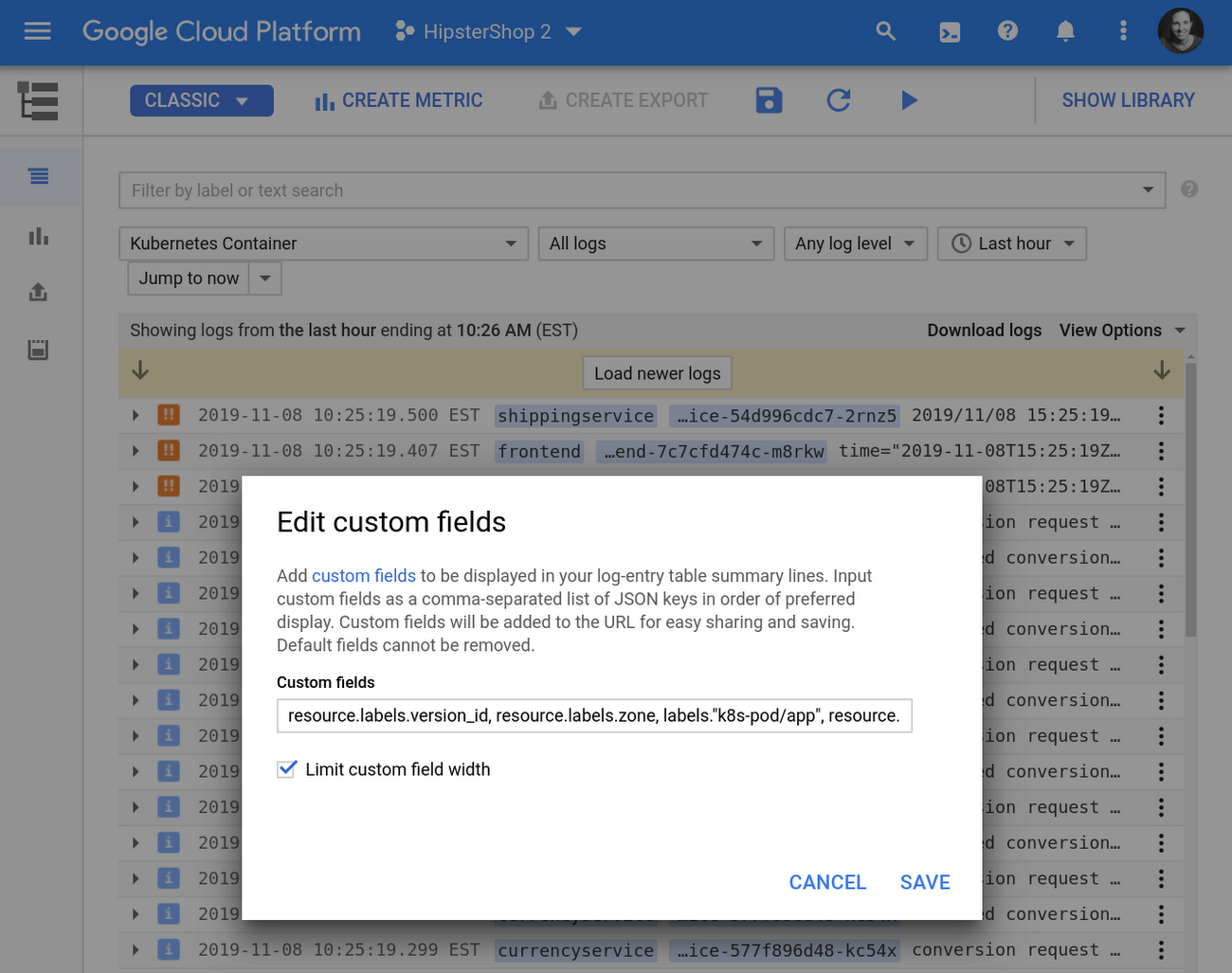
A menudo hay un campo específico oculto en sus entradas de registro que es de particular interés cuando analiza los registros. Puede personalizar los resultados de búsqueda para incluir este campo haciendo clic en un campo y seleccionando “Agregar campo a la línea de resumen”. También puede agregar, eliminar o reorganizar campos manualmente, o alternar el control que limita su ancho en Ver opciones. Esta configuración puede acelerar drásticamente la resolución de problemas, ya que obtiene el contexto necesario en resumen. Vea un ejemplo aquí:
2 Personaliza tus resultados de búsqueda.png
- Guarde sus búsquedas favoritas y resultados de búsqueda personalizados en su biblioteca de búsqueda personal
A menudo escuchamos que usa las mismas búsquedas una y otra vez, o que desea poder guardar configuraciones de campo personalizadas para realizar búsquedas futuras. Por lo tanto, recientemente lanzamos una nueva función que le permite guardar sus búsquedas, incluidos los campos personalizados en su propia biblioteca.
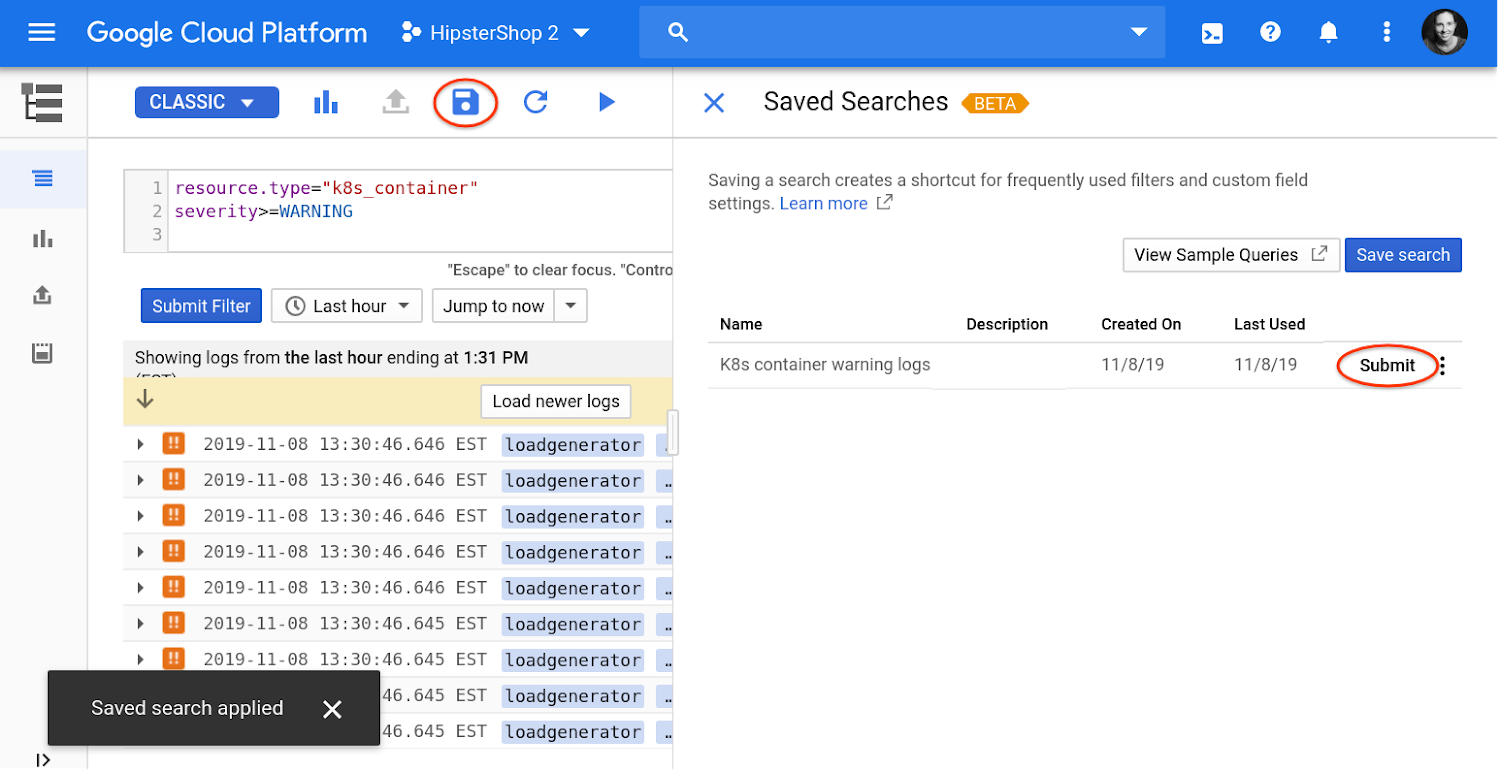
Puede compartir sus búsquedas guardadas con usuarios que tienen permisos en su proyecto haciendo clic en el selector junto a Enviar y luego en Vista previa. Haga clic en el enlace Copiar para filtrar y compartirlo con su equipo. Esta función se encuentra actualmente en versión beta, y continuaremos trabajando en la funcionalidad de la biblioteca de consultas para ayudarlo a analizar rápidamente sus registros.Use métricas basadas en registros para paneles y alertas
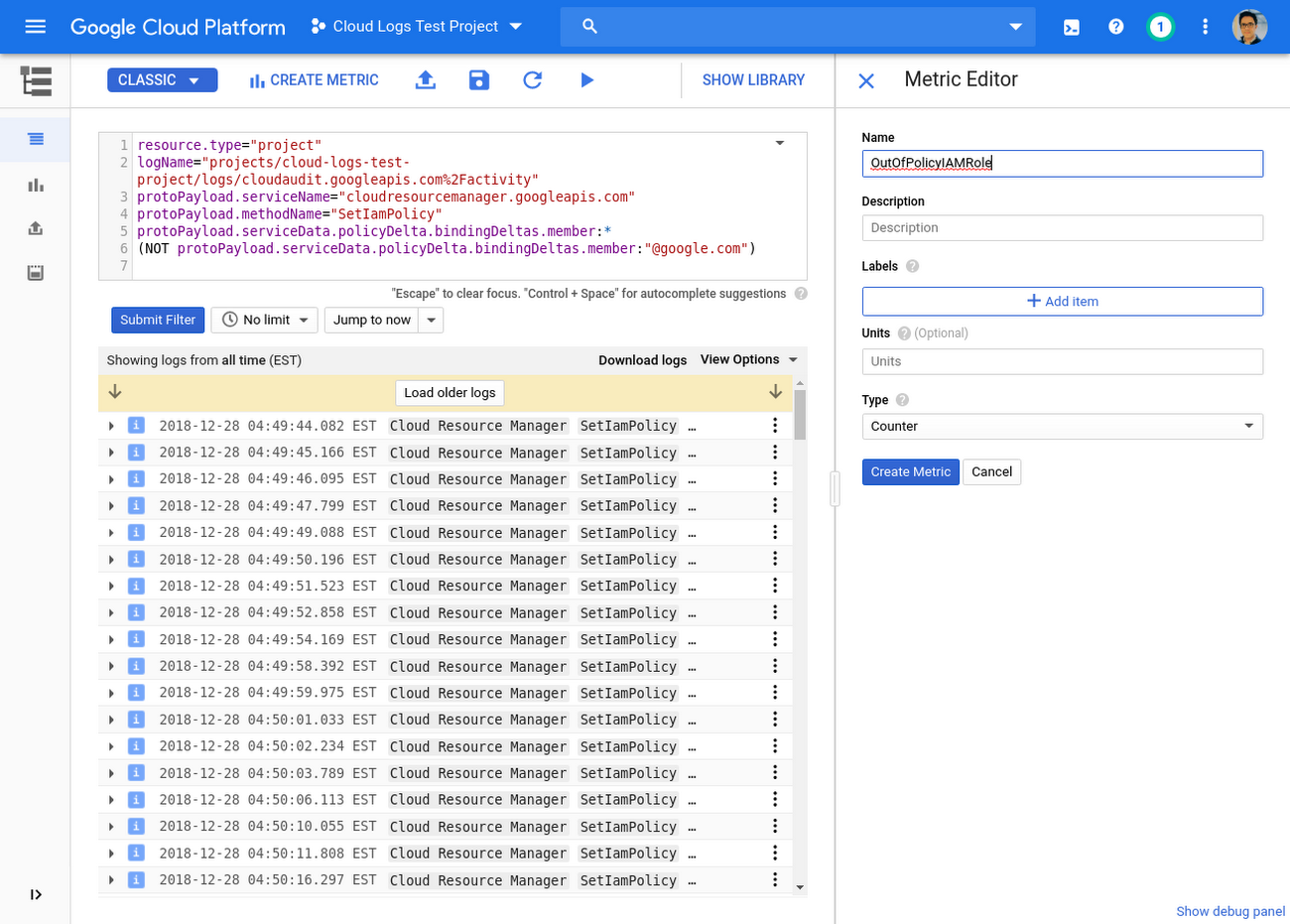
Ahora que ha dominado las consultas avanzadas, puede llevar su análisis al siguiente nivel con monitoreo en tiempo real utilizando métricas basadas en registros. Por ejemplo, suponga que desea recibir una alerta cada vez que alguien concede acceso a una dirección de correo electrónico desde fuera de su organización. Puede crear una métrica para que coincida con los registros de auditoría de las llamadas SetIamPolicy de Cloud Resource Manager, donde un miembro que no esté en el dominio “my-org.com” tiene acceso, como se muestra aquí:
resource.type="project" logName="projects/[PROJECT_ID]/logs/cloudaudit.googleapis.com%2Factivity" protoPayload.serviceName="cloudresourcemanager.googleapis.com" protoPayload.methodName="SetIamPolicy" protoPayload.serviceData.policyDelta.bindingDeltas.member:* (NOT protoPayload.serviceData.policyDelta.bindingDeltas.member:"@my-org.com")
Con el conjunto de filtros, simplemente haga clic en Crear métrica y asígnele un nombre.
Para alertar si llega un registro coincidente, seleccione Crear alerta desde métrica en el menú de tres puntos al lado de su métrica definida por el usuario recién creada. Esto abrirá una nueva política de alertas en Stackdriver Monitoring. Cambie el agregador a “suma” y el umbral a 0 para “Valor más reciente” para que reciba una alerta cada vez que se produzca un registro coincidente. No se preocupe si todavía no hay datos, ya que su métrica solo contará las entradas de registro desde que se creó.
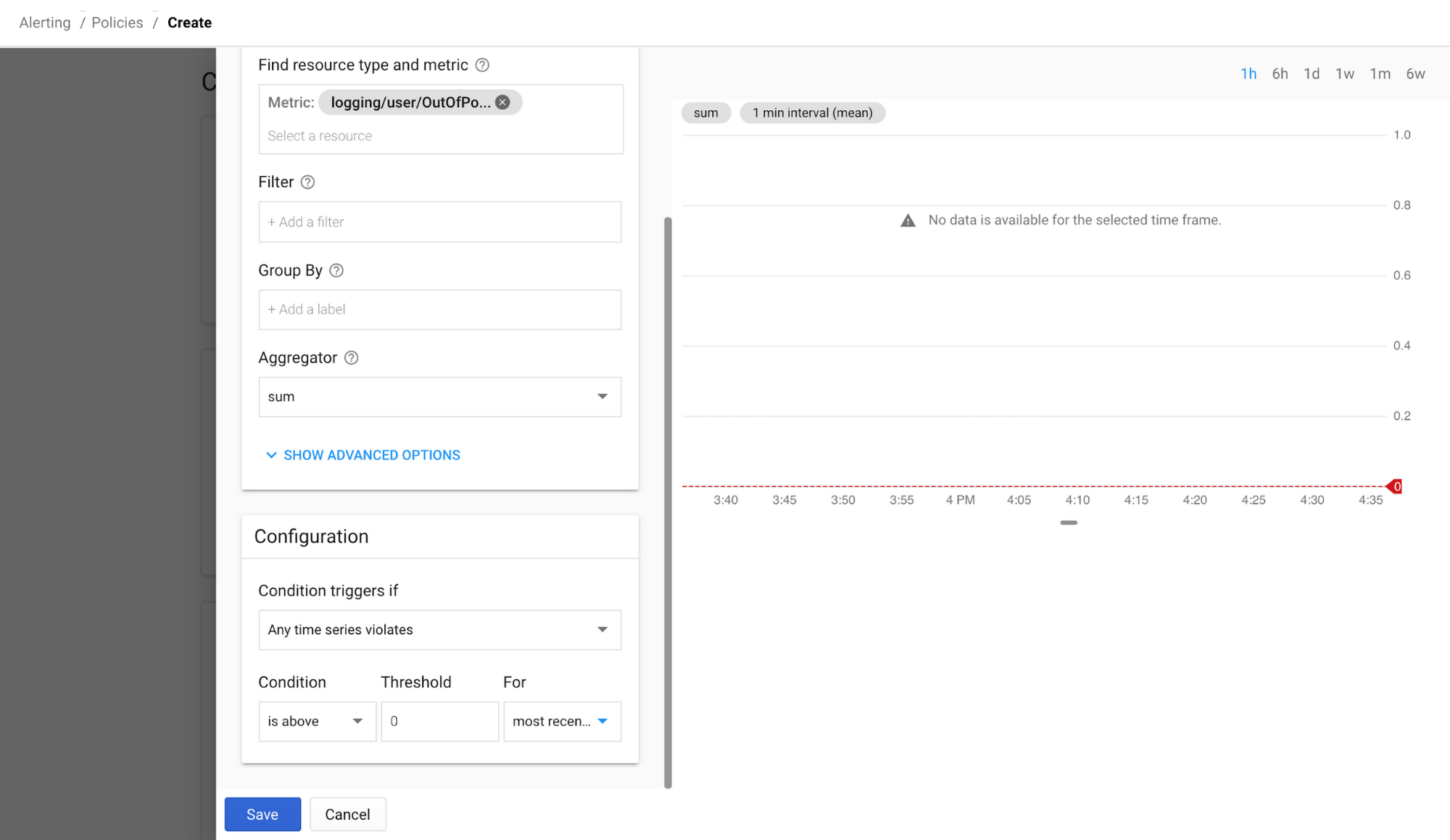
Además, puede agregar una dirección de correo electrónico, un canal de Slack, un SMS o una cuenta y nombre de PagerDuty, y guardar sus alertas
política. También puede agregar estas métricas a los paneles junto con métricas personalizadas y del sistema.
- Realice consultas SQL más rápidas en registros en BigQuery utilizando tablas particionadas
Stackdriver Logging admite el envío de registros a BigQuery mediante sumideros de registros para realizar análisis avanzados mediante SQL o unirse a otras fuentes de datos, como la facturación en la nube. Hemos escuchado de usted que sería más fácil analizar registros en varios días en BigQuery si admitiéramos tablas particionadas. Así que recientemente agregamos esta opción de tablas particionadas que simplifica las consultas SQL en los registros en BigQuery.
Al crear un sumidero para exportar sus registros a BigQuery, puede usar tablas con fecha o tablas particionadas. La selección predeterminada es una tabla dividida en fecha, en la que se agrega un sufijo _YYYYMMDD al nombre de la tabla para crear tablas diarias basadas en la marca de tiempo en la entrada del registro. Las tablas divididas en fecha tienen algunas desventajas que pueden agregarse a la sobrecarga de consultas:
Consultar varios días es más difícil, ya que necesita usar el operador UNION para simular la partición.
BigQuery necesita mantener una copia del esquema y los metadatos para cada tabla con nombre de fecha.
Es posible que se requiera BigQuery para verificar los permisos para cada tabla consultada.
Al crear un sumidero de registro, ahora puede seleccionar la opción Usar tablas particionadas para usar tablas particionadas en BigQuery para superar cualquier problema con las tablas divididas por fecha.
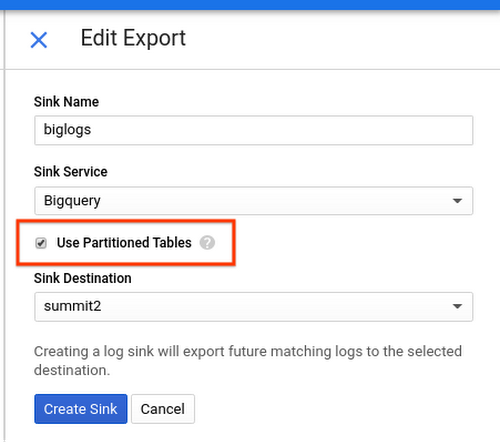
Los registros transmitidos a una tabla particionada usan el campo de marca de tiempo de la entrada del registro para escribir en la partición correcta. Las consultas en tales tablas particionadas en tiempo de ingestión pueden especificar filtros de predicado en la pseudocolumna _PARTITIONTIME o _PARTITIONDATE para limitar la cantidad de registros escaneados. Puede especificar un rango de fechas usando un filtro WHERE, como este:
WHERE _PARTITIONTIME BETWEEN TIMESTAMP(“20191101”) AND TIMESTAMP(“20191105”)